Accelerate Gemma 4 Inference Up to 3x with Multi-Token Prediction: A Step-by-Step Guide
Introduction
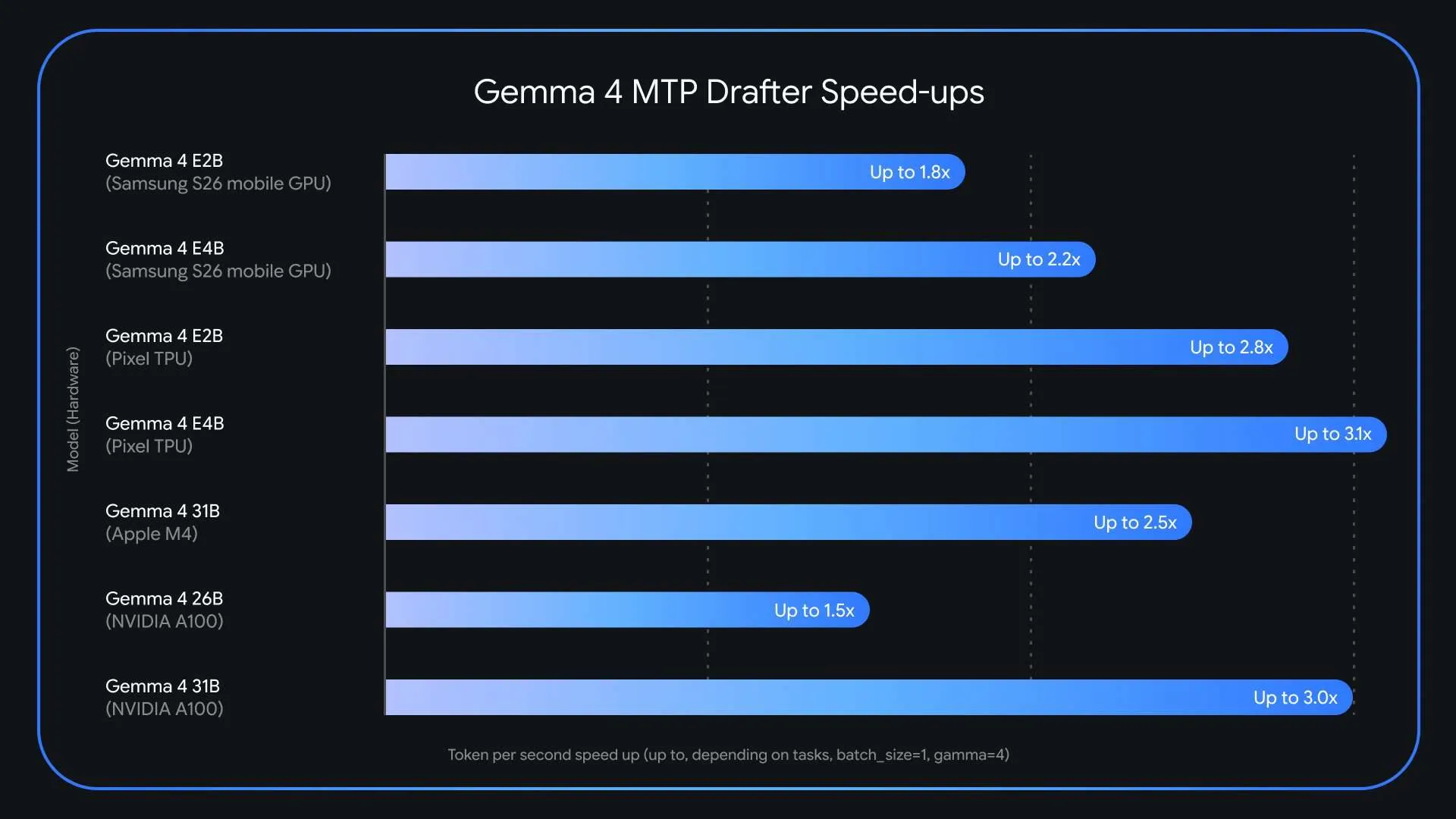
Large language models like Gemma 4 are incredibly powerful, but their inference speed often becomes a bottleneck in production. The core issue is the memory-bandwidth bottleneck: each token generated requires loading billions of parameters from VRAM, leaving compute units idle. Google has released Multi-Token Prediction (MTP) drafters for the Gemma 4 family, a specialized speculative decoding architecture that can triple inference speed without any loss in output quality or reasoning accuracy. This guide walks you through implementing MTP drafters to accelerate your Gemma 4 deployment.
What You Need
- Gemma 4 Model Weights – Access to Gemma 4 14B or 31B base models (available on Hugging Face and Google's repository).
- MTP Drafter Weights – The separate lightweight drafter model (also available from the same sources).
- Compatible Hardware – A GPU with sufficient VRAM (e.g., A100 80GB for Gemma 4 31B, or a smaller GPU for 14B).
- Python Environment – Python 3.10+ with PyTorch 2.0+ and the
transformerslibrary (v4.45+). - Optional – vLLM or other inference frameworks that support speculative decoding for better performance.
Step-by-Step Guide
Step 1: Understand the Memory-Bandwidth Bottleneck
Before diving into implementation, it helps to grasp why LLMs are slow. Standard autoregressive decoding generates one token at a time. For every token, the entire model must be loaded from VRAM to compute units. This is memory-bandwidth bound—the GPU's compute capacity is underutilized because data transfer is the limiting factor. Even trivially predictable tokens (like after "Actions speak louder than…") require the same heavyweight computation. MTP addresses this by letting a small drafter model propose multiple tokens quickly, then having the target model verify them all in one parallel pass.
Step 2: Get Access to Gemma 4 and MTP Drafters
Download the necessary models from Hugging Face or Google's official repository. You'll need:
- Target model:
google/gemma-4-31borgoogle/gemma-4-14b. - Drafter model:
google/gemma-4-14b-mtp-drafter(for the 31B target) or similar (the MTP drafter for the 14B target is typically a smaller variant).
transformers library's AutoModelForCausalLM to load them. Note: you must accept the license on Hugging Face if applicable.Step 3: Set Up Speculative Decoding Pipeline
Load both models in your Python script. The drafter model is used as an assistant to the main model. Here's a basic setup:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "google/gemma-4-31b"
drafter_name = "google/gemma-4-14b-mtp-drafter"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
drafter = AutoModelForCausalLM.from_pretrained(drafter_name, device_map="auto")
Ensure both models are on the same device and that device_map="auto" works for your GPU.
Step 4: Run Inference with MTP
Use the generate method with the assistant_model parameter. This triggers speculative decoding. Example:
prompt = "The future of AI is"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
assistant_model=drafter,
max_new_tokens=256,
do_sample=False # or True for creative tasks
)
print(tokenizer.decode(outputs[0]))
The drafter proposes multiple future tokens; the target model verifies them in one forward pass. The result is identical to standard decoding (lossless speedup) but up to 3× faster.
Step 5: Verify Output Quality
Because the target model always verifies the draft, the output distribution is mathematically identical to running the target model alone. To confirm, compare outputs from standard decoding (without assistant_model) and with MTP on a few prompts. They should match exactly. If using sampling (do_sample=True), you may need to set the same random seed for deterministic comparison.
Step 6: Tune for Maximum Speedup
The default draft length is typically 4–6 tokens. Experiment with num_assistant_tokens parameter (if supported) or the max_length of the drafter. Longer drafts can increase speedup but may lower acceptance rate. Monitor GPU utilization; you want high compute usage. Also consider batch size: using larger batches improves throughput, but watch VRAM. For batch inference, MTP works similarly—just feed multiple prompts and the drafter proposes drafts for each.
Tips for Success
- Check compatibility: Ensure your
transformersversion supportsassistant_model(v4.41+). For vLLM, look for speculative decoding integration. - Profile your setup: Measure latency per token with and without MTP to confirm speedup.
- VRAM management: MTP requires loading two models. For Gemma 4 31B (originally ~62GB in FP16) plus a 14B drafter (~28GB), you need an 80GB GPU. For smaller setups, use the 14B target with a 2.6B drafter.
- Experiment with temperature: For creative tasks, higher temperature may reduce acceptance rate; adjust draft length accordingly.
- Use in production: MTP is fully compatible with streaming and APIs—no changes to inference contract.
Multi-Token Prediction is a game-changer for deploying Gemma 4 in real-time applications. By following these steps, you can achieve up to 3× faster inference without any quality loss. Start experimenting today and unlock the full potential of your LLM deployment.